Table of Contents
Overview of the ForkOperator
The ForkOperator is a type of control operators that allow a task flow to branch into multiple streams (or forked branches) as represented by a Fork, each of which goes to a separately configured sink with its own data writer. The ForkOperator gives users more flexibility in terms of controlling where and how ingested data should be output. This is useful for situations, e.g., that data records need to be written into multiple different storages, or that data records need to be written out to the same storage (say, HDFS) but in different forms for different downstream consumers. The best practices of using the ForkOperator that we recommend, though, are discussed below. The diagram below illustrates how the ForkOperator in a Gobblin task flow allows an input stream to be forked into multiple output streams, each of which can have its own converters, quality checkers, and writers.
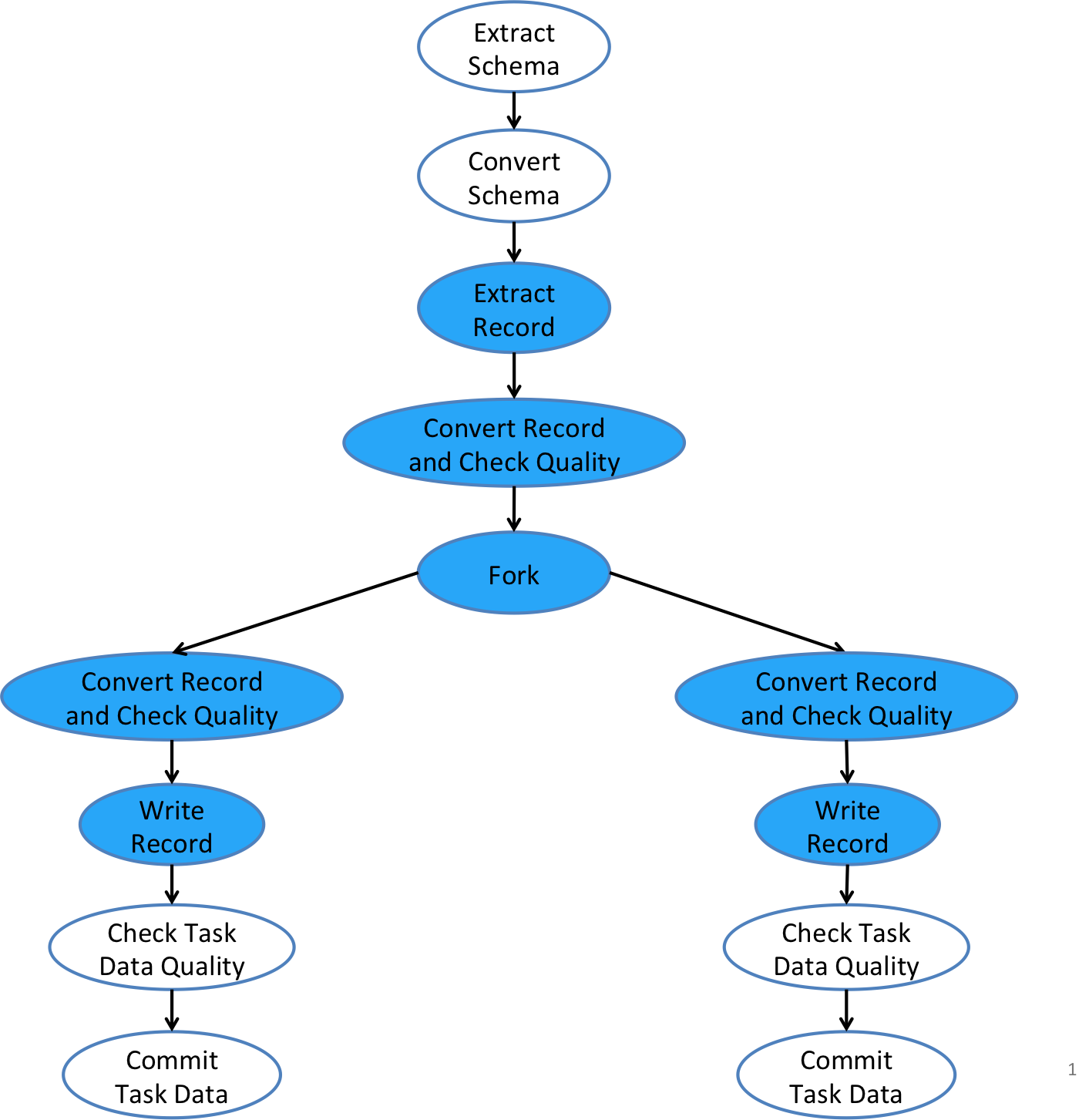
Gobblin Task Flow
Using the ForkOperator
Basics of Usage
The ForkOperator, like most other operators in a Gobblin task flow, is pluggable through the configuration, or more specifically , the configuration property fork.operator.class that points to a class that implements the ForkOperator interface. For instance:
fork.operator.class=org.apache.gobblin.fork.IdentityForkOperator
By default, if no ForkOperator class is specified, internally Gobblin uses the default implementation IdentityForkOperator with a single forked branch (although it does supports multiple forked branches). The IdentityForkOperator simply unconditionally forwards the schema and ingested data records to all the forked branches, the number of which is specified through the configuration property fork.branches with a default value of 1. When an IdentityForkOperator instance is initialized, it will read the value of fork.branches and use that as the return value of getBranches.
The expected number of forked branches is given by the method getBranches of the ForkOperator. This number must match the size of the list of Booleans returned by forkSchema as well as the size of the list of Booleans returned by forkDataRecords. Otherwise, ForkBranchMismatchException will be thrown. Note that the ForkOperator itself is not making and returning a copy for the input schema and data records, but rather just providing a Boolean for each forked branch telling if the schema or data records should be in each particular branch. Each forked branch has a branch index starting at 0. So if there are three forked branches, the branches will have indices 0, 1, and 2, respectively. Branch indices are useful to tell which branch the Gobblin task flow is in. Each branch also has a name associated with it that can be specified using the configuration property fork.branch.name.<branch index>. Note that the branch index is added as a suffix to the property name in this case. More on this later. If the user does not specify a name for the branches, the names in the form fork_<branch index> will be used.
The use of the ForkOperator with the possibility that the schema and/or data records may be forwarded to more than one forked branches has some special requirement on the input schema and data records to the ForkOperator. Specifically, because the same schema or data records may be forwarded to more than branches that may alter the schema or data records in place, it is necessary for the Gobblin task flow to make a copy of the input schema or data records for each forked branch so any modification within one branch won't affect any other branches.
To guarantee that it is always able to make a copy in such a case, Gobblin requires the input schema and data records to be of type Copyable when there are more than one forked branch. Copyable is an interface that defines a method copy for making a copy of an instance of a given type. The Gobblin task flow will check if the input schema and data records are instances of Copyable and throw a CopyNotSupportedException if not. This check is performed independently on the schema first and data records subsequently. Note that this requirement is enforced if and only if the schema or data records are to be forwarded to more than one branches, which is the case if forkSchema or forkDataRecord returns a list containing more than one TRUE. Having more than one branch does not necessarily mean the schema and/or data records need to be Copyable.
Gobblin ships with some built-in Copyable implementations, e.g., CopyableSchema and CopyableGenericRecord for Avro's Schema and GenericRecord.
Per-Fork Configuration
Since each forked branch may have it's own converters, quality checkers, and writers, in addition to the ones in the pre-fork stream (which does not have a writer apparently), there must be a way to tell the converter, quality checker, and writer classes of one branch from another and from the pre-fork stream. Gobblin uses a pretty straightforward approach: if a configuration property is used to specify something for a branch in a multi-branch use case, the branch index should be appended as a suffix to the property name. The original configuration name without the suffix is generally reserved for the pre-fork stream. For example, converter.classes.0 and converter.classes.1 are used to specify the list of converter classes for branch 0 and 1, respectively, whereas converter.classes is reserved for the pre-fork stream. If there's only a single branch (the default case), then the index suffix is not applicable. Without being a comprehensive list, the following groups of built-in configuration properties may be used with branch indices as suffices to specify things for forked branches:
- Converter configuration properties: configuration properties whose names start with
converter. - Quality checker configuration properties: configuration properties whose names start with
qualitychecker. - Writer configuration properties: configuration properties whose names start with
writer.
Failure Semantics
In a normal task flow where the default IdentityForkOperator with a single branch is used, the failure of the single branch also means the failure of the task flow. When there are more than one forked branch, however, the failure semantics are more involved. Gobblin uses the following failure semantics in this case:
- The failure of any forked branch means the failure of the whole task flow, i.e., the task succeeds if and only if all the forked branches succeed.
- A forked branch stops processing any outstanding incoming data records in the queue if it fails in the middle of processing the data.
- The failure and subsequent stop/completion of any forked branch does not prevent other branches from processing their copies of the ingested data records. The task will wait until all the branches to finish, regardless if they succeed or fail.
- The commit of output data of forks is determined by the job commit policy (see
JobCommitPolicy) specified. IfJobCommitPolicy.COMMIT_ON_FULL_SUCCESS(orfullin short) is used, the output data of the entire job will be discarded if any forked branch fails, which will fail the task and consequently the job. If insteadJobCommitPolicy.COMMIT_SUCCESSFUL_TASKS(orsuccessfulin short) is used, output data of tasks whose forked branches all succeed will be committed. Output data of any task that has at least one failed forked branch will not be committed since the the task is considered failed in this case. This also means output data of the successful forked branches of the task won't be committed either.
Performance Tuning
Internally, each forked branch as represented by a Fork maintains a bounded record queue (implemented by BoundedBlockingRecordQueue), which serves as a buffer between the pre-fork stream and the forked stream of the particular branch. The size if this bounded record queue can be configured through the property fork.record.queue.capacity. A larger queue allows for more data records to be buffered therefore giving the producer (the pre-fork stream) more head room to move forward. On the other hand, a larger queue requires more memory. The bounded record queue imposes a timeout time on all blocking operations such as putting a new record to the tail and polling a record off the head of the queue. Tuning the queue size and timeout time together offers a lot of flexibility and a tradeoff between queuing performance vs. memory consumption.
In terms of the number of forked branches, we have seen use cases with a half dozen forked branches, and we are anticipating uses cases with much larger numbers. Again, when using a large number of forked branches, the size of the record queues and the timeout time need to be carefully tuned.
The BoundedBlockingRecordQueue in each Fork keeps trach of the following queue statistics that can be output to the logs if the DEBUG logging level is turned on. Those statistics provide good indications on the performance of the forks.
- Queue size, i.e., the number of records in queue.
- Queue fill ratio, i.e., a ratio of the number of records in queue over the queue capacity.
- Put attempt rate (per second).
- Total put attempt count.
- Get attempt rate (per second).
- Total get attempt count.
Comparison with PartitionedDataWriter
Gobblin ships with a special type of DataWriters called PartitionedDataWriter that allow ingested records to be written in a partitioned fashion using a WriterPartitioner into different locations in the same sink. The WriterPartitioner determines the specific partition for each data record. So there's certain overlap in terms of functionality between the ForkOperator and PartitionedDataWriter. The question is which one should be used under which circumstances? Below is a summary of the major differences between the two operators.
- The
ForkOperatorrequires the number of forked branches to be known and returned throughgetBranchesbefore the task starts, whereas thePartitionedDataWriterdoes not have this requirement. - The
PartitionedDataWriterwrites each data record to a single partition, whereas theForkOperatorallows data records to be forwarded to any number of forked branches. - The
ForkOperatorallows the use of additional converters and quality checkers in any forked branches before data gets written out. ThePartitionedDataWriteris the last operator in a task flow. - Use of the
ForkOperatorallows data records to be written to different sinks, whereas thePartitionedDataWriteris not capable of doing this. - The
PartitionedDataWriterwrites data records sequentially in a single thread, whereas use of theForkOperatorallows forked branches to write independently in parallel sinceForks are executed in a thread pool.
Writing your Own ForkOperator
Since the built-in default implementation IdentityForkOperator simply blindly forks the input schema and data records to every branches, it's often necessary to have a custom implementation of the ForkOperator interface for more fine-grained control on the actual branching. Checkout the interface ForkOperator for the methods that need to be implemented. You will also find the ForkOperatorUtils to be handy when writing your own ForkOperator implementations.
Best Practices
The ForkOperator can have many potential use cases and we have seen the following common ones:
- Using a
ForkOperatorto write the same ingested data to multiple sinks, e.g., HDFS and S3, possibly in different formats. This kind of use cases is often referred to as "dual writes", which are generally NOT recommended as "dual writes" may lead to data inconsistency between the sinks in case of write failures. However, with the failure semantics discussed above, data inconsistency generally should not happen with the job commit policyJobCommitPolicy.COMMIT_ON_FULL_SUCCESSorJobCommitPolicy.COMMIT_SUCCESSFUL_TASKS. This is because a failure of any forked branch means the failure of the task and none of the forked branches of the task will have its output data committed, making inconsistent output data between different sinks impossible. - Using a
ForkOperatorto process ingested data records in different ways conditionally. For example, aForkOperatormay be used to classify and write ingested data records to different places on HDFS depending on some field in the data that serves as a classifier. - Using a
ForkOperatorto group ingested data records of a certain schema type in case the incoming stream mixes data records of different schema types. For example, we have seen a use case in which a single Kafka topic is used for records of various schema types and when data gets ingested to HDFS, the records need to be written to different paths according to their schema types.
Generally, a common use case of the ForkOperator is to route ingested data records so they get written to different output locations conditionally. The ForkOperator also finds common usage for "dual writes" to different sinks potentially in different formats if the job commit policy JobCommitPolicy.COMMIT_ON_FULL_SUCCESS (or full in short) or JobCommitPolicy.COMMIT_SUCCESSFUL_TASKS (or successful in short) is used, as explained above.
Troubleshooting
1) When using Forks with jobs defined as Hocon, you may encounter an error like:
com.typesafe.config.ConfigException$BugOrBroken: In the map, path 'converter.classes' occurs as both the parent object of a value and as a value. Because Map has no defined ordering, this is a broken situation.
at com.typesafe.config.impl.PropertiesParser.fromPathMap(PropertiesParser.java:115)
at com.typesafe.config.impl.PropertiesParser.fromPathMap(PropertiesParser.java:82)
at com.typesafe.config.impl.ConfigImpl.fromAnyRef(ConfigImpl.java:260)
at com.typesafe.config.impl.ConfigImpl.fromPathMap(ConfigImpl.java:200)
at com.typesafe.config.ConfigFactory.parseMap(ConfigFactory.java:855)
at com.typesafe.config.ConfigFactory.parseMap(ConfigFactory.java:866)
at gobblin.runtime.embedded.EmbeddedGobblin.getSysConfig(EmbeddedGobblin.java:497)
at gobblin.runtime.embedded.EmbeddedGobblin.runAsync(EmbeddedGobblin.java:442)
This is because in Hocon a key can have only a single type (see: https://github.com/lightbend/config/blob/master/HOCON.md#java-properties-mapping).
To solve this, try writing your config like:
```
converter.classes.ROOT_VALUE="..."
...
converter.classes.0="..."
...
converter.classes.1="..."
```
Example
Let's take a look at one example that shows how to work with the ForkOperator for a real use case. Say you have a Gobblin job that ingests Avro data from a data source that may have some sensitive data in some of the fields that need to be purged. Depending on if data records have sensitive data, they need to be written to different locations on the same sink, which we assume is HDFS. So essentially the tasks of the job need a mechanism to conditionally write ingested data records to different locations depending if they have sensitive data. The ForkOperator offers a way of implementing this mechanism.
In this particular use case, we need a ForkOperator implementation of two branches that forwards the schema to both branches but each data record to only one of the two branches. The default IdentityForkOperator cannot be used since it simply forwards every data records to every branches. So we need a custom implementation of the ForkOperator and let's simply call it SensitiveDataAwareForkOperator under the package gobblin.example.fork. Let's also assume that branch 0 is for data records with sensitive data, whereas branch 1 is for data records without. Below is a brief sketch of how the implementation looks like:
public class SensitiveDataAwareForkOperator implements ForkOperator<Schema, GenericRecord> {
private static final int NUM_BRANCHES = 2;
@Override
public void init(WorkUnitState workUnitState) {
}
@Override
public int getBranches(WorkUnitState workUnitState) {
return NUM_BRANCHES;
}
@Override
public List<Boolean> forkSchema(WorkUnitState workUnitState, Schema schema) {
// The schema goes to both branches.
return ImmutableList.of(Boolean.TRUE, Boolean.TRUE);
}
@Override
public List<Boolean> forkDataRecord(WorkUnitState workUnitState, GenericRecord record) {
// Data records only go to one of the two branches depending on if they have sensitive data.
// Branch 0 is for data records with sensitive data and branch 1 is for data records without.
// hasSensitiveData checks the record and returns true of the record has sensitive data and false otherwise.
if (hasSensitiveData(record)) {
return ImmutableList.of(Boolean.TRUE, Boolean.FALSE)
}
return ImmutableList.of(Boolean.FALSE, Boolean.TRUE);
}
@Override
public void close() throws IOException {
}
}
To make the example more concrete, let's assume that the job uses some converters and quality checkers before the schema and data records reach the SensitiveDataAwareForkOperator, and it also uses a converter to purge the sensitive fields and a quality checker that makes sure some mandatory fields exist for purged data records in branch 0. Both branches will be written to the same HDFS but into different locations.
fork.operator.class=org.apache.gobblin.example.fork.SensitiveDataAwareForkOperator
# Pre-fork or non-fork-specific configuration properties
converter.classes=<Converter classes used in the task flow prior to OutlierAwareForkOperator>
qualitychecker.task.policies=org.apache.gobblin.policies.count.RowCountPolicy,org.apache.gobblin.policies.schema.SchemaCompatibilityPolicy
qualitychecker.task.policy.types=OPTIONAL,OPTIONAL
data.publisher.type=org.apache.gobblin.publisher.BaseDataPublisher
# Configuration properties for branch 0
converter.classes.0=org.apache.gobblin.example.converter.PurgingConverter
qualitychecker.task.policies.0=org.apache.gobblin.example,policies.MandatoryFieldExistencePolicy
qualitychecker.task.policy.types.0=FAILED
writer.fs.uri.0=hdfs://<namenode host>:<namenode port>/
writer.destination.type.0=HDFS
writer.output.format.0=AVRO
writer.staging.dir.0=/gobblin/example/task-staging/purged
writer.output.dir.0=/gobblin/example/task-output/purged
data.publisher.final.dir.0=/gobblin/example/job-output/purged
# Configuration properties for branch 1
writer.fs.uri.1=hdfs://<namenode host>:<namenode port>/
writer.destination.type.1=HDFS
writer.output.format.1=AVRO
writer.staging.dir.1=/gobblin/example/task-staging/normal
writer.output.dir.1=/gobblin/example/task-output/normal
data.publisher.final.dir.1=/gobblin/example/job-output/normal