Table of Contents
Introduction
There are multiple challenges in dataset configuration management in the context of ETL data processing as ETL infrastructure employs multi-state processing flows to ingest and publish data on HDFS. Here are some examples types of datasets and types of processing:
- OLTP Snapshots: ingest, publishing, replication, retention management, compliance post-processing
- OLTP Increments: ingest, publishing, replication, roll-up, compaction, retention management
- Streaming data: ingest, publishing, roll-up of streaming data, retention management, compliance post-processing
- Opaque (derived) data: replication, retention management
A typical dataset could be a database table, a Kafka topic, etc. Current the customization of the dataset processing is typically achieved through file/directory blacklists/whitelists in job/flow level configurations. This approach suffers from a number issues:
- Dataset unaware - control is done through low-level file/directory wildcards which can be hard to understand for more complex data layouts.
- Difficulty in using/applying policies, i.e. applying the same configuration settings to large number of datasets.
- Non-intuitive - the use of blacklists and whitelists can lead to properties whose effect is not always clear.
- A large potential of inconsistencies across different jobs/flows.
- Lack of version control
- Lack of easy, aggregated view of the setup/configuration for a given dataset across all flows (including consumer access)
We want to have a new way to customize the processing of each dataset like enabling/disabling certain types of processing, specific SLAs, access restrictions, retention policies, etc. without previous mentioned problems.
Dataset Config Management Requirement
Design a backend and flexible client library for storing, managing and accessing configuration that can be used to customize the process of thousands of datasets across multiple systems/flows.
Data Model
- (Dataset) configs are identified by a string config key
- Each config key is mapped to a config object (a collection of properties)
- The config object should be extensible, i.e. we should be able to add properties with arbitrary names
- Hierarchical system for overrides
- Global default values
- Children datasets override/inherit parent dataset configs
- Ability to group properties that are specific for a group of datasets (aka tags). For example, we should be able to tag a group of Kafka datasets as "High-priority" and associate specific configuration properties with these settings.
- Tags should can be applied to both datasets and other tags.
- Support for references to other properties (parameter expansion)
- Late expansion of references (at time of access)
Versioning
- Generated configs have a monotonically increasing version number
- Generated configs have a date of generation
- Once published configurations are immutable
- Easy rollback to a previous version
- Even if rolled back, a configuration is still available for processes that already use it
- Audit traces about changes to configuration
Client library
- Always loads the latest (non-rollbacked) configuration version (as of time of initialization). Once the version is fixed, the same version should be used for the remained of the processing. The consistency is needed only within a process.
- Non-requirement: cross-process version consistency. The application needs to enforce consistency across processes if necessary, e.g. by copying the config to a stable location.
- Ability to list the tags (policies) associated with a dataset.
- Ability to list datasets associated with a tag. For example, we should be able to have a flow which can discover and process only "High-priority" datasets.
- Debug info how values were derived in generated configs (e.g. from where a property value was inherited)
Config Store
- Each config store is represented by an URI path
- The URI path is significant so that configs can be associated at every level. For example, for the dataset URI hdfs_store:/data/databases/DB/Table , we should be able to associate config at every level: /data/databases/DB/Table, /data/databases/DB/, /data/databases/, etc.
Current Dataset Config Management Implementation
At a very high-level, we extend typesafe config with:
- Support for logical include URIs
- Abstraction of a Config Store
- Config versioning
- Ability to traverse the ”import” relationships
Data model
Config key (configuration node) / config value
For our use cases, we can define each configuration node per data set. All the configuration related to that dataset are specified together.
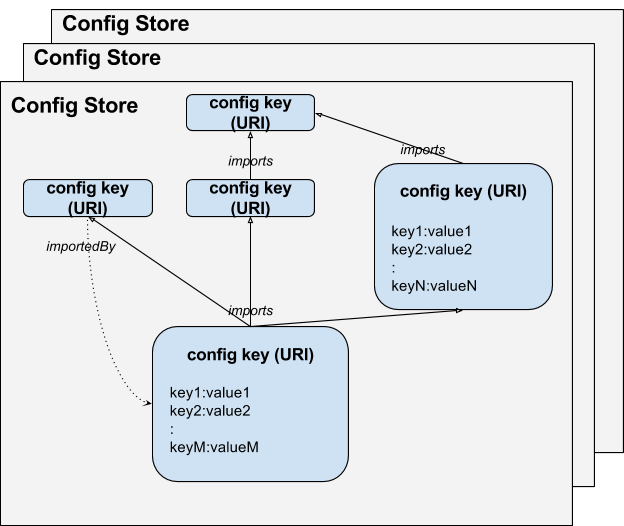
Essentially, the system provides a mapping from a config key to a config object. Each config key is represented through a URI. The config object is a map from property name to a property value. We refer to this as own config (object) and refer to it through the function own_config(K, property_name) = property_value.
A config key K can import one or more config keys I1, I2, ... . The config key K will inherit any properties from I1, I2, … that are not defined in K. The inheritance is resolved in the order of the keys I1, I2, … etc., i.e. the property will be resolved to the value in the last one that defines the property. This is similar to including configs in typesafe config. We will refer to resulting configuration as own config (object) and denote it though the function resolved_config(K, property_name) = property_value .
We also use the path in the config key URI for implicit tagging. For example, /data/tracking/TOPIC implicitly imports /data/tracking/, which implicitly imports /data/ which implicitly imports /. Note that all these URI are considered as config Key so their path level implicitly indicates importation. For a given config key, all implicit imports are before the explicit imports, i.e. they have lower priority in resolution. Typical use case for this implicit importation can be a global default configuration file in root path applied to all files under it. Files in this root path can have their own setting overriding the default value inherited from root path's file.
Tags
For our use cases, we can define the static tags in a well known file per dataset.
Dynamic tags Some tags cannot be applied statically at “compile” time. For example, such are cluster-specific tags since they are on the environment where the client application runs. We will support such tags about allowing the use of limited number of variables when importing another config key. For example, such a variable can be “local_cluster.name”. Then, importing /data/tracking/${local_cluster.name} can provide cluster-specific overrides.
Config Store The configuration is partitioned in a number of Config Stores . Each Config Store is:
- mapped to a unique URI scheme;
- responsible for managing the mapping of config keys (represented through URIs with the Config Store scheme) to unresolved configs;
Client application
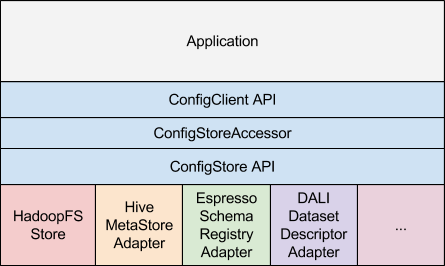
The client application interacts using the ConfigClient API . The ConfigClient maintains a set of ConfigStoreAccessor objects which interact through the ConfigStore API with the appropriate ConfigStore implementation depending on the scheme of the ConfigStore URI . There can be a native implementation of the API like the HadoopFS ConfigStore or an adapter to an existing config/metadata store like the Hive MetaStore, etc
File System layout
- All configurations in one configuration store reside in it’s ROOT directory
- _CONFIG_STORE file in ROOT directory (identification file for configuration store)
- One or multiple version directories under ROOT
- In each version, each directory represented as one configuration node
- In each directory, the main.conf file specify the configuration for that node
- In each directory, the includes file specify the imports links
Example of a config store
ROOT
├── _CONFIG_STORE (contents = latest non-rolled-back version)
└── 1.0.53 (version directory)
├── data
│ └── tracking
│ ├── TOPIC
│ │ ├── includes (imports links)
│ │ └── main.conf (configuration file)
│ ├── includes
│ └── main.conf
└── tags
├── tracking
│ └── retention
│ └── LONG
│ │ ├── includes
│ │ └── main.conf
│ └── main.conf
└── acl
└── restricted
├── main.conf
└── secdata
├── includes
└── main.conf