Table of Contents
This page has two parts. Section 1 is an instruction on how to carry over checkpoints between two runs of a scheduled batch ingestion job, so that each run can start at where the previous run left off. Section 2 is a deep dive of different types of states in Gobblin and how they are used in a typical job run.
Managing Watermarks in a Job
When scheduling a Gobblin job to run in batches and pull data incrementally, each run, upon finishing its tasks, should check in the state of its work into the state store, so that the next run can continue the work based on the previous run. This is done through a concept called Watermark.
Basics
low watermark and expected high watermark
When the Source creates WorkUnits, each WorkUnit should generally contain a low watermark and an expected high watermark. They are the start and finish points for the corresponding task, and the task is expected to pull the data from the low watermark to the expected high watermark.
actual high watermark
When a task finishes extracting data, it should write the actual high watermark into its WorkUnitState. To do so, the Extractor may maintain a nextWatermark field, and in Extractor.close(), call this.workUnitState.setActualHighWatermark(this.nextWatermark). The actual high Watermark is normally the same as the expected high Watermark if the task completes successfully, and may be smaller than the expected high Watermark if the task failed or timed-out. In some cases, the expected high watermark may not be available so the actual high watermark is the only stat available that tells where the previous run left off.
In the next run, the Source will call SourceState.getPreviousWorkUnitStates() which should contain the actual high watermarks the last run checked in, to be used as the low watermarks of the new run.
watermark type
A watermark can be of any custom type by implementing the Watermark interface. For example, for Kafka-HDFS ingestion, if each WorkUnit is responsible for pulling a single Kafka topic partition, a watermark is a single long value representing a Kafka offset. If each WorkUnit is responsible for pulling multiple Kafka topic partitions, a watermark can be a list of long values, such as MultiLongWatermark.
Task Failures
A task may pull some data and then fail. If a task fails and job commit policy specified by configuration property job.commit.policy is set to full, the data it pulled won't be published. In this case, it doesn't matter what value Extractor.nextWatermark is, the actual high watermark will be automatically rolled back to the low watermark by Gobblin internally. On the other hand, if the commit policy is set to partial, the failed task may get committed and the data may get published. In this case the Extractor is responsible for setting the correct actual high watermark in Extractor.close(). Therefore, it is recommended that the Extractor update nextWatermark every time it pulls a record, so that nextWatermark is always up to date (unless you are OK with the next run re-doing the work which may cause some data to be published twice).
Multi-Dataset Jobs
Currently the only state store implementation Gobblin provides is FsStateStore which uses Hadoop SequenceFiles to store the states. By default, each job run reads the SequenceFile created by the previous run, and generates a new SequenceFile. This creates a pitfall when a job pulls data from multiple datasets: if a data set is skipped in a job run for whatever reason (e.g., it is blacklisted), its watermark will be unavailable for the next run.
Example: suppose we schedule a Gobblin job to pull a Kafka topic from a Kafka broker, which has 10 partitions. In this case each partition is a dataset. In one of the job runs, a partition is skipped due to either being blacklisted or some failure. If no WorkUnit is created for this partition, this partition's watermark will not be checked in to the state store, and will not be available for the next run.
The are two solutions to the above problem (three if you count the one that implements a different state store that behaves differently and doesn't have this problem).
Solution 1: make sure to create a WorkUnit for every dataset. Even if a dataset should be skipped, an empty WorkUnit should still be created for the dataset ('empty' means low watermark = expected high watermark).
Solution 2: use Dataset URNs. When a job pulls multiple datasets, the Source class may define a URN for each dataset, e.g., we may use PageViewEvent.5 as the URN of the 5th partition of topic PageViewEvent. When the Source creates the WorkUnit for this partition, it should set property dataset.urn in this WorkUnit with value PageViewEvent.5. This is the solution gobblin current uses to support jobs pulling data for multiple datasets.
If different WorkUnits have different values of dataset.urn, the job will create one state store SequenceFile for each dataset.urn. In the next run, instead of calling SourceState.getPreviousWorkUnitStates(), one should use SourceState.getPreviousWorkUnitStatesByDatasetUrns(). In this way, each run will look for the most recent state store SequenceFile for each dataset, and therefore, even if a dataset is not processed by a job run, its watermark won't be lost.
Note that when using Dataset URNs, each WorkUnit can only have one dataset.urn, which means, for example, in the Kafka ingestion case, each WorkUnit can only process one partition. This is usually not a big problem except that it may output too many small files (as explained in Kafka HDFS ingestion, by having a WorkUnit pull multiple partitions of the same topic, these partitions can share output files). On the other hand, different WorkUnits may have the same dataset.urn.
Gobblin State Deep Dive
Gobblin involves several types of states during a job run, such as JobState, TaskState, WorkUnit, etc. They all extend the State class, which is a wrapper around Properties and provides some useful utility functions.
State class hierarchy
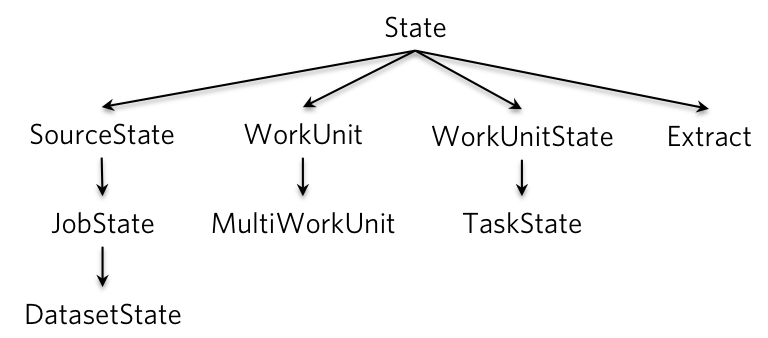
SourceState,JobStateandDatasetState:SourceStatecontains properties that define the current job run. It contains properties in the job config file, and the states the previous run persisted in the state store. It is passed to Source to createWorkUnits.
Compared to SourceState, a JobState also contains properties of a job run such as job ID, starting time, end time, etc., as well as status of a job run, e.g, PENDING, RUNNING, COMMITTED, FAILED, etc.
When the data pulled by a job is separated into different datasets (by using dataset.urn explained above), each dataset will have a DatasetState object in the JobState, and each dataset will persist its states separately.
WorkUnitandMultiWorkUnit: AWorkUnitdefines a unit of work. It may contain properties such as which data set to be pulled, where to start (low watermark), where to finish (expected high watermark), among others. AMultiWorkUnitcontains one or moreWorkUnits. AllWorkUnits in aMultiWorkUnitwill be run by a single Task.
The MultiWorkUnit is useful for finer-grained control and load balancing. Without MultiWorkUnits, if the number of WorkUnits exceeds the number of mappers in the MR mode, the job launcher can only balance the number of WorkUnits in the mappers. If different WorkUnits have very different workloads (e.g., some pull from very large partitions and others pull from small partitions), this may lead to mapper skew. With MultiWorkUnit, if the Source class knows or can estimate the workload of the WorkUnits, it can pack a large number of WorkUnits into a smaller number of MultiWorkUnits using its own logic, achieving better load balancing.
-
WorkUnitStateandTaskState: AWorkUnitStatecontains the runtime properties of aWorkUnit, e.g., actual high watermark, as well as the status of a WorkUnit, e.g.,PENDING,RUNNING,COMMITTED,FAILED, etc. ATaskStateadditionally contains properties of a Task that runs aWorkUnit, e.g., task ID, start time, end time, etc. -
Extract:Extractis mainly used for ingesting from databases. It contains properties such as job type (snapshot-only, append-only, snapshot-append), primary keys, delta fields, etc.
How States are Used in a Gobblin Job
-
When a job run starts, the job launcher first creates a
JobState, which contains (1) all properties specified in the job config file, and (2) theJobState/DatasetStateof the previous run, which contains, among other properties, the actual high watermark the previous run checked in for each of its tasks / datasets. -
The job launcher then passes the
JobState(as aSourceStateobject) to theSource, based on which theSourcewill create a set ofWorkUnits. Note that when creatingWorkUnits, theSourceshould not add properties inSourceStateinto theWorkUnits, which will be done when eachWorkUnitis executed in aTask. The reason is that since the job launcher runs in a single JVM, creating a large number ofWorkUnits, each containing a copy of theSourceState, may cause OOM. -
The job launcher prepares to run the
WorkUnits. - In standalone mode, the job launcher will add properties in the
JobStateinto eachWorkUnit(if a property inJobStatealready exists in theWorkUnit, it will NOT be overwritten, i.e., the value in theWorkUnittakes precedence). Then for eachWorkUnitit creates aTaskto run theWorkUnit, and submits all these Tasks to aTaskExecutorwhich will run theseTasks in a thread pool. - In MR mode, the job launcher will serialize the
JobStateand eachWorkUnitinto a file, which will be picked up by the mappers. It then creates, configures and submits a Hadoop job.
After this step, the job launcher will be waiting till all tasks finish.
-
Each
Taskcorresponding to aWorkUnitcontains aTaskState. TheTaskStateinitially contains all properties inJobStateand the correspondingWorkUnit, and during the Task run, more runtime properties can be added toTaskStatebyExtractor,ConverterandWriter, such as the actual high watermark explained in Section 1. -
After all
Tasks finish,DatasetStates will be created from allTaskStates based on thedataset.urnspecified in theWorkUnits. For each dataset whose data is committed, the job launcher will persist itsDatasetState. If nodataset.urnis specified, there will be a single DatasetState, and thus the DatasetState will be persisted if either allTasks successfully committed, or some task failed but the commit policy is set topartial, in which case the watermarks of these failed tasks will be rolled back, as explained in Section 1.