Companies powered by Gobblin















Leverage Gobblin
Startup: Standalone
Run Gobblin as a standalone application on a single box or JVM, or simply run in embedded mode with your application.

Enterprise: Big Data
Run Gobblin as a map-reduce application on multiple Hadoop versions. You can also leverage workflow schedulers like Azkaban to launch MR jobs.

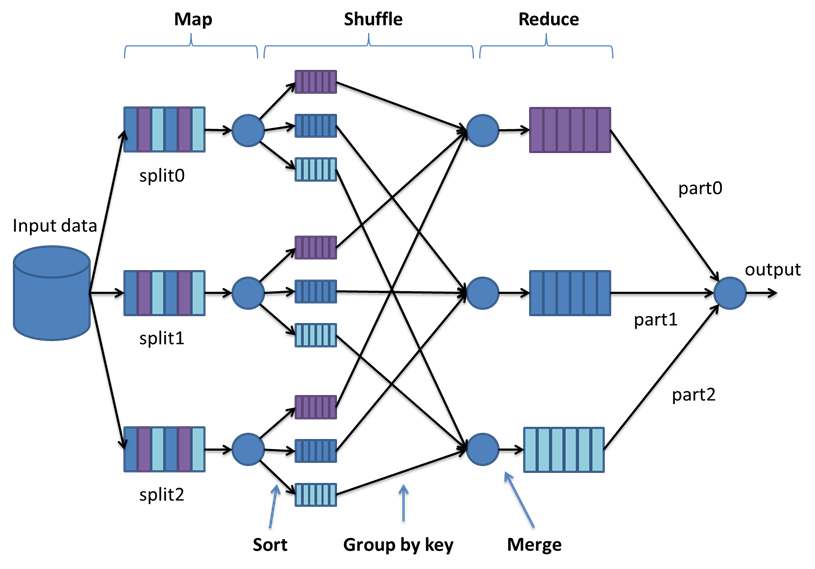
Enterprise: Streaming
Run Gobblin as a standalone cluster with primary and secondary nodes on Yarn or Kubernetes. This mode also supports HA.

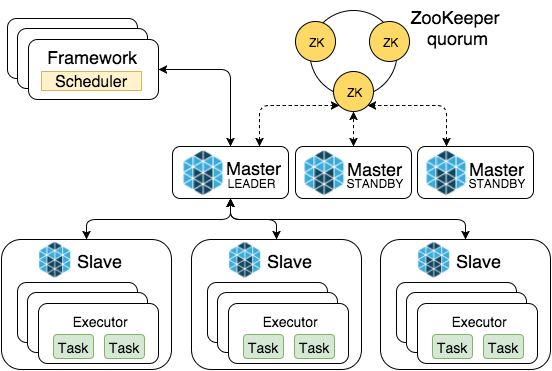
Enterprise: Cloud Native
Run Gobblin as an elastic cluster on public clouds like AWS (Azure and GCP support coming soon). This mode also supports HA.

Presentations / Use-cases of Gobblin
Stream and Batch Data Integration at LinkedIn scale using Apache Gobblin - Abhishek Tiwari
Next-Gen Data Movement Platform at PayPal - Jay Sen
How we Gobble data at Prezi - Tamas Nemeth
Foundations for a Data-Driven Marketing Engine at Machine Zone - Michael Dreibelbis
Gobblin for Data Analytics at Intel - Seshu Edala, Dave Shaefer, Nghia Ngo
Gobblin at Nerdwallet - Akshay Nanavati & Eric Ogren
The Bird Project for US Department of Energy by Sandia National Laboratories
Use of Gobblin alongside Kafka at CERN - Manuel Martin Marquez